The Mathematical Underpinnings of Large Language Models in Machine Learning
As we continue our exploration into the depths of machine learning, it becomes increasingly clear that the success of large language models (LLMs) hinges on a robust foundation in mathematical principles. From the algorithms that drive understanding and generation of text to the optimization techniques that fine-tune performance, mathematics forms the backbone of these advanced AI systems.
Understanding the Core: Algebra and Probability in LLMs
At the heart of every large language model, such as GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers), lies linear algebra combined with probability theory. These models learn to predict the probability of a word or sequence of words occurring in a sentence, an application deeply rooted in statistics.
- Linear Algebra: Essential for managing the vast matrices that represent the embeddings and transformations within neural networks, enabling operations that capture patterns in data.
- Probability: Provides the backbone for understanding and predicting language through Markov models and softmax functions, crucial for generating coherent and contextually relevant text.
Deep Dive: Vector Spaces and Embeddings
Vector spaces, a concept from linear algebra, are paramount in translating words into numerical representations. These embeddings capture semantic relationships, such as similarity and analogy, enabling LLMs to process text in a mathematically tractable way.
<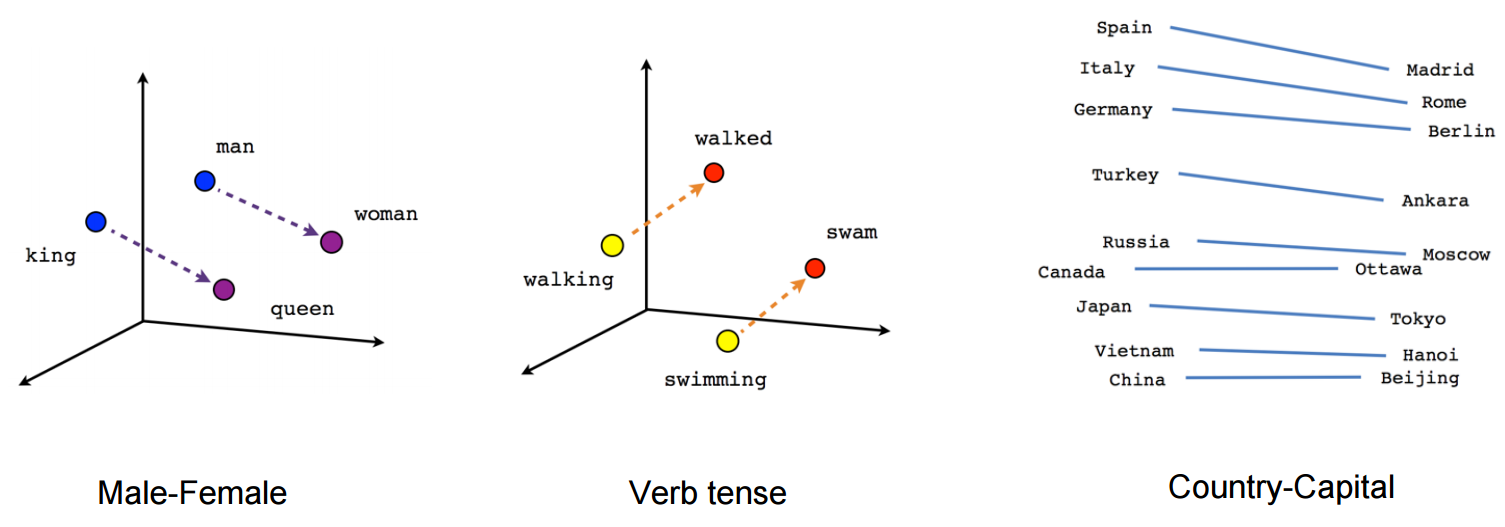 >
>
Optimization: The role of Calculus in Training AI Models
Training an LLM is fundamentally an optimization problem. Techniques from calculus, specifically gradient descent and its variants, are employed to minimize the difference between the model’s predictions and actual outcomes. This process iteratively adjusts the model’s parameters (weights) to improve its performance on a given task.
<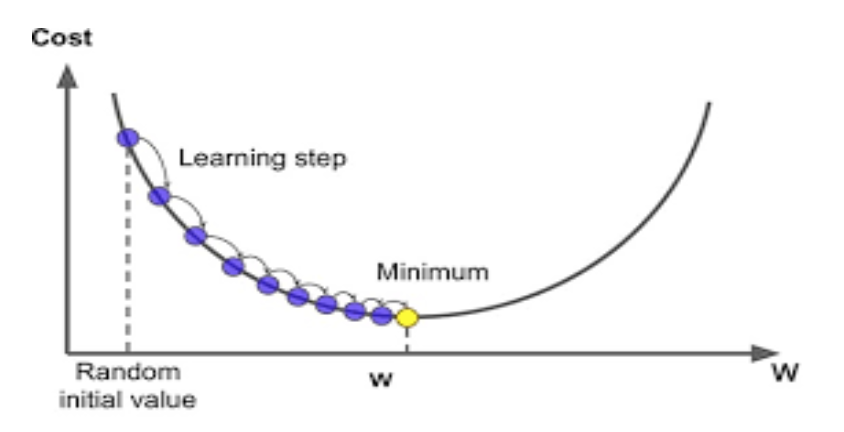 >
>
Dimensionality Reduction: Enhancing Model Efficiency
In previous discussions, we delved into dimensionality reduction’s role in LLMs. Techniques like PCA (Principal Component Analysis) and t-SNE (t-distributed Stochastic Neighbor Embedding) are instrumental in compressing information while preserving the essence of data, leading to more efficient computation and potentially uncovering hidden patterns within the language.
Case Study: Maximizing Cloud Efficiency Through Mathematical Optimization
My work in cloud solutions, detailed at DBGM Consulting, demonstrates the practical application of these mathematical principles. By leveraging calculus-based resource optimization techniques, we can achieve peak efficiency in cloud deployments, a concept I explored in a previous article on maximizing cloud efficiency through calculus.
Looking Ahead: The Future of LLMs and Mathematical Foundations
The future of large language models is inextricably linked to advances in our understanding and application of mathematical concepts. As we push the boundaries of what’s possible with AI, interdisciplinary research in mathematics will be critical in addressing the challenges of scalability, efficiency, and ethical AI development.
Continuous Learning and Adaptation
The field of machine learning is dynamic, necessitating a commitment to continuous learning. Keeping abreast of new mathematical techniques and understanding their application within AI will be crucial for anyone in the field, mirroring my own journey from a foundation in AI at Harvard to practical implementations in consulting.
< >
>
Conclusion
In sum, the journey of expanding the capabilities of large language models is grounded in mathematics. From algebra and calculus to probability and optimization, these foundational elements not only power current innovations but will also light the way forward. As we chart the future of AI, embracing the complexity and beauty of mathematics will be essential in unlocking the full potential of machine learning technologies.
Focus Keyphrase: Mathematical foundations of machine learning