The Integral Role of Calculus in Artificial Intelligence and Machine Learning
In the vast and constantly evolving fields of Artificial Intelligence (AI) and Machine Learning (ML), the significance of foundational mathematical concepts cannot be overstated. Among these, Calculus, specifically, plays a pivotal role in shaping the algorithms that are at the heart of AI and ML models. In this article, we’ll delve into a specific concept within Calculus that is indispensable in AI and ML: Gradient Descent. Moreover, we will illustrate how this mathematical concept is utilized to solve broader problems, a task that aligns perfectly with my expertise at DBGM Consulting, Inc.
Understanding Gradient Descent
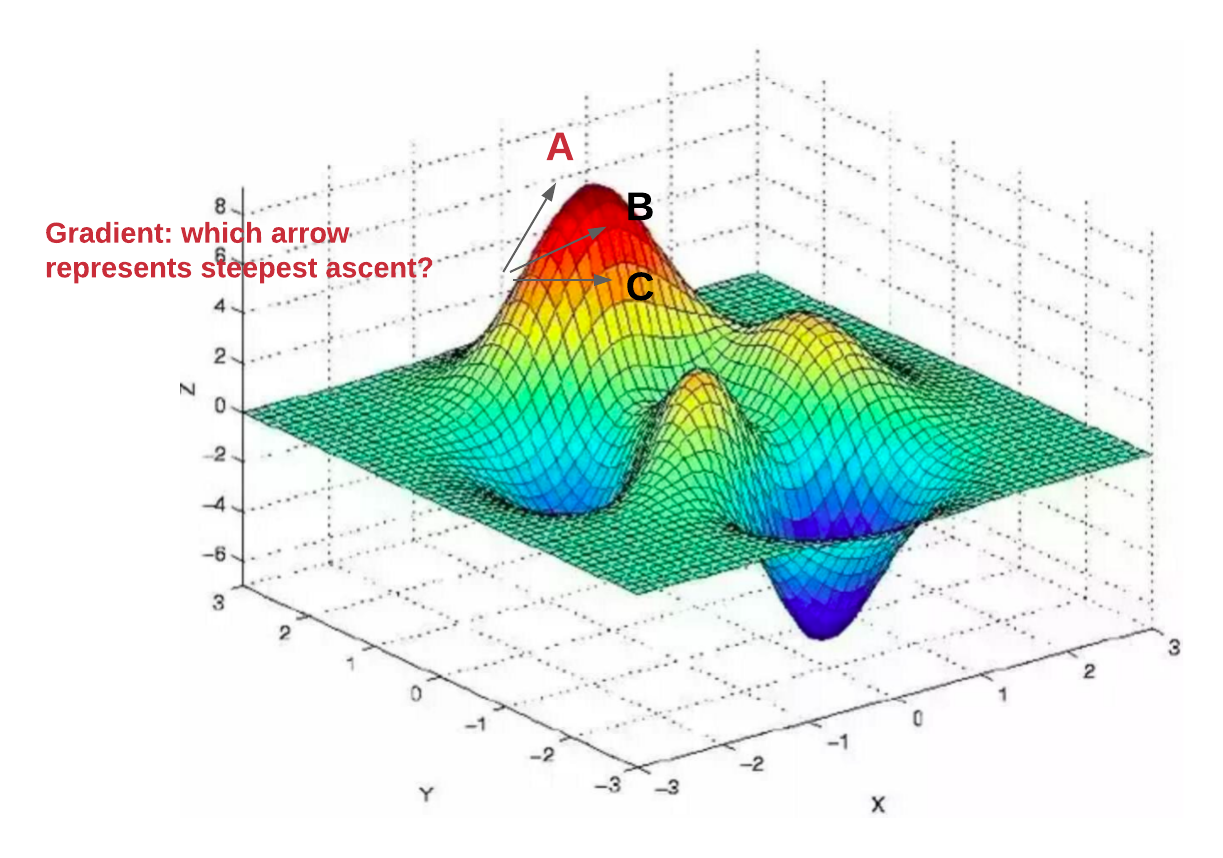
Gradient Descent is a first-order iterative optimization algorithm used to minimize a function. In essence, it involves taking small steps in the direction of the function’s steepest descent, guided by its gradient. The formula used to update the parameters in Gradient Descent is given by:
θ = θ - α ∇θ J(θ)
where:
θrepresents the parameters of the function or model.αis the learning rate, determining the size of the steps taken.∇θ J(θ)is the gradient of the objective functionJ(θ)with respect to the parametersθ.
This optimization method is particularly vital in the field of ML, where it is used to minimize the loss function, adjusting the weights of the network to improve prediction accuracy.
Application in AI and ML
Considering my background in developing machine learning models for self-driving robots at Harvard University, the application of Gradient Descent is a daily reality. For instance, in ensuring that an autonomous vehicle can correctly interpret its surroundings and make informed decisions, we optimize algorithms to discern patterns within vast datasets, an endeavor where Gradient Descent proves invaluable.
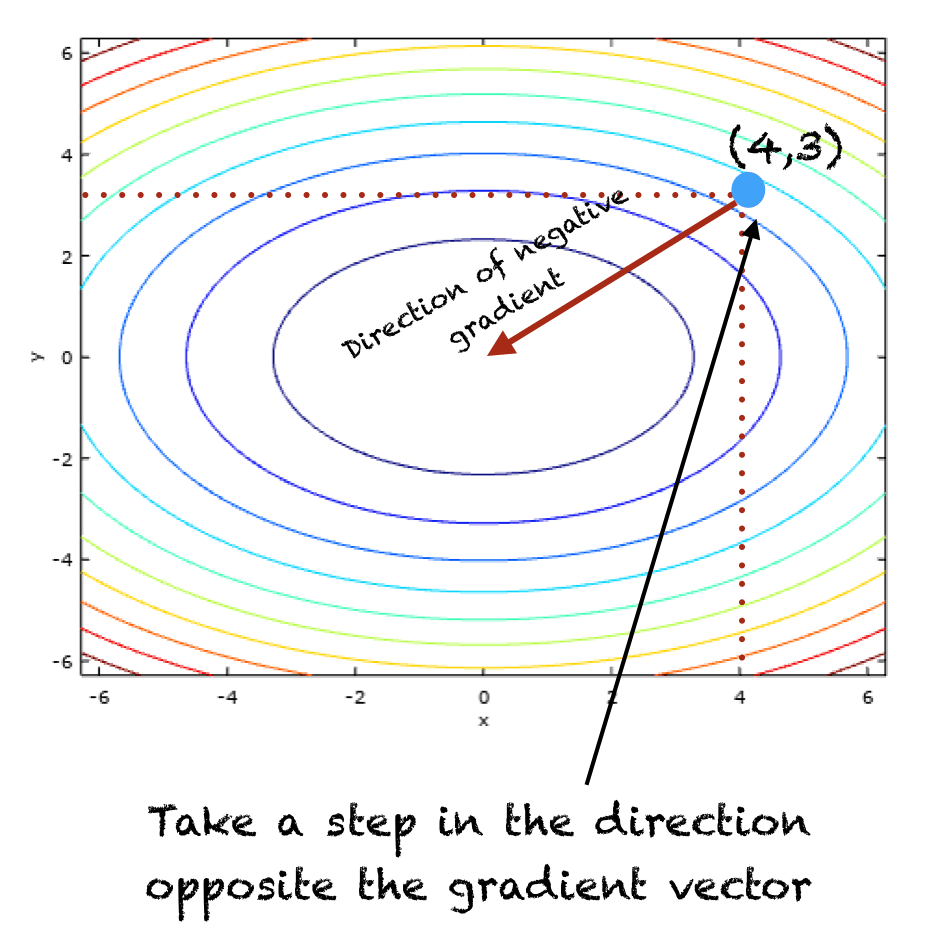
The iterative nature of Gradient Descent, moving steadily towards the minimum of a function, mirrors the process of refining an AI model’s accuracy over time, by learning from data and adjusting its parameters accordingly. This optimization process is not just limited to robotics but extends across various domains within AI and ML such as natural language processing, computer vision, and predictive analytics.
Connecting Calculus to Previous Discussions
In light of our prior exploration into concepts like Large Language Models (LLMs) and Bayesian Networks, the underpinning role of Calculus, especially through optimization techniques like Gradient Descent, reveals its widespread impact. For example, optimizing the performance of LLMs, as discussed in “Exploring the Future of Large Language Models in AI and ML,” necessitates an intricate understanding of Calculus to navigate the complexities of high-dimensional data spaces effectively.
Moreover, our delve into the mathematical foundations of machine learning highlights how Calculus not only facilitates the execution of complex algorithms but also aids in conceptualizing the theoretical frameworks that empower AI and ML advancements.
Conclusion
Gradient Descent exemplifies the symbiotic relationship between Calculus and the computational models that drive progress in AI and ML. As we continue to push the boundaries of what AI can achieve, grounding our innovations in solid mathematical understanding remains paramount. This endeavor resonates with my vision at DBGM Consulting, where leveraging deep technical expertise to solve real-world problems forms the cornerstone of our mission.
 >
> >
> >
>