The Future of Search: AI with Confidence and Consistency
As we move further into the age of Artificial Intelligence, it’s clear that many people are beginning to express the desire for AI models—like ChatGPT—not only to assist with tasks but to redefine how we search the internet. The idea is simple: rather than relying on traditional search engines, users want an AI that can synthesize answers from multiple sources while avoiding the all-too-familiar pitfall of incorrect or misleading information, often termed “AI hallucination.” In this evolving field, OpenAI’s recent advancements are particularly exciting for those of us working in AI and machine learning.
### A New Era of Internet Search
Today, most individuals use search engines like Google to answer simple questions. But sometimes, Google falls short for more complex tasks such as planning detailed trips or finding specialized information. Imagine asking an AI not only for trip recommendations but for weather preferences, accommodation reviews, and even specific restaurant suggestions—all tied to your personal tastes. The integration of ChatGPT-like models will soon make these interactions more personalized and data-driven, but what makes this approach truly revolutionary is that it cites sources, mitigating the chance of misinformation.
This feature, often requested by researchers and professionals, ensures that users receive not just aggregated data but enriched content with credibility established through references. It’s this exact capability that allows AI to compete with or complement traditional search engines, taking us into uncharted territories of information retrieval.
* *
*
### Addressing the Issue of Hallucination
A key problem with synthesizing information at this level is that AI systems sometimes make things up. This phenomenon, referred to as “hallucination” in the AI community, has the potential to harm AI’s reliability. Imagine relying on a search engine that produces not only ad-heavy or irrelevant results but outright falsehoods. The damage could be significant, especially for academic researchers or professionals who depend on accurate data.
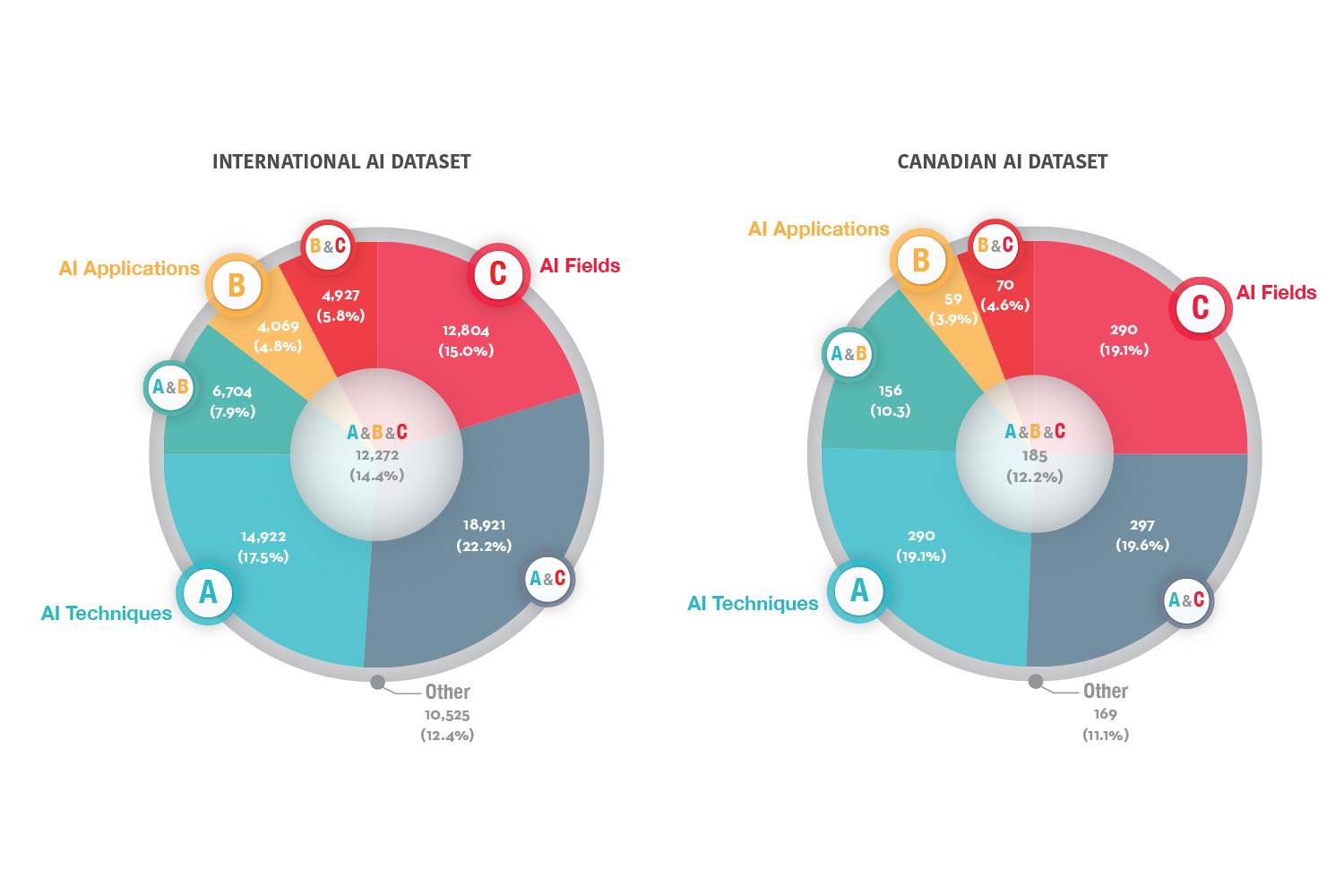
Fortunately, OpenAI has tackled this problem head-on, developing new datasets tailored specifically to test the model’s ability to answer difficult questions with greater confidence and accuracy. Their approach integrates consistent evaluation to stop hallucinations in their tracks before they can affect real-world application.
While at Harvard, where I focused on Machine Learning and Information Systems, I frequently worked with datasets, testing different models. OpenAI’s method of using a dataset curated for correctness across multiple domains is a leap forward. It’s not simply about feeding AI more data, but about feeding it the right data—questions where blind guessing won’t cut it. This is how we as engineers can make AI models more reliable.
### AI Awareness and Confidence
As AI continues to evolve, an important consideration arises: how aware are these models of their own fallibility? We humans know when we’re uncertain, but can AI models do the same? According to the latest research, it turns out they can. These AIs are increasingly capable of assessing their confidence levels. If the AI is unsure, it adjusts its responses to reflect this uncertainty, a lifeline for professionals using AI as a secondary tool for research or decision making.
When comparing flagship AI models such as GPT-4 with their less advanced counterparts, the results are staggering. Flagship models were found to be more consistent and confident in their outputs. Of course, whether it’s analyzing stock trends or answering complex queries, the goal is improving not only accuracy but consistency across multiple instances of the same question.
Consistency remains one of AI’s biggest hurdles, but based on OpenAI’s latest findings, their flagship reasoning model significantly outperforms smaller, less advanced models. For anyone operating in machine learning or relying on AI data-driven applications—like the work I’ve done for self-driving robot systems—it is evident this software evolution is paving the way for fewer errors and tighter, more reliable predictions.
*
*
### Revolutionizing AI-Based Search
This leads me to the most exciting application: using these advancements directly in search. Having an AI that can deliver refined, accurate, and consistent results opens up new possibilities. Imagine planning a backyard renovation and asking for tailored answers—all without spending hours sifting through irrelevant search results. Or getting intricate responses for more nuanced questions, such as the evolution of AI models into autonomous vehicles or ethical frameworks for AI-assisted medical diagnoses.
These improvements naturally make me think of some past entries in my blog, particularly those focused on **machine learning challenges**, where misinformation and bias can derail the best-laid projects. It seems OpenAI’s approach offers a promising solution to these challenges, ensuring that AI stays aware of its limitations.
While there’s still much road to cover before AI is totally trustworthy for all tasks, we’re entering an era where inaccuracies are caught sooner, and consistency emerges as a crucial component of AI applications. For those of us—technologists, scholars, and enthusiasts—working towards the integration of AI into everyday life, it truly is a fascinating time to be involved.
* *
*
### The Road Ahead
It’s incredibly promising that AI is becoming more ‘self-aware’ when it comes to reporting confidence levels and providing citations. Moving forward, these developments could transform how businesses and consumers interact with information. Whether it’s stock data analysis, personalized search for trip planning, or querying complex astronomical phenomena, AI’s ability to reduce “hallucination” and increase precision bodes well for the future of this technology.
As someone who has worked extensively in cloud technology, AI process automation, and data science, I am optimistic but cautiously observing these trends. While advancements are happening at a breakneck pace, we must ensure checks and balances like the ones OpenAI is implementing remain a priority. By nurturing an AI model that is careful in its confidence, sources, and consistency, we mitigate the risk of the widespread negative effects from incorrect data.
In short, it’s an exciting time for those of us deeply involved in AI development and its intersection with practical, day-to-day applications. OpenAI’s research and development have unlocked doors for more reliable and efficient AI-driven web services, perhaps fundamentally reshaping how each of us interacts with the vast information available online.
*
*