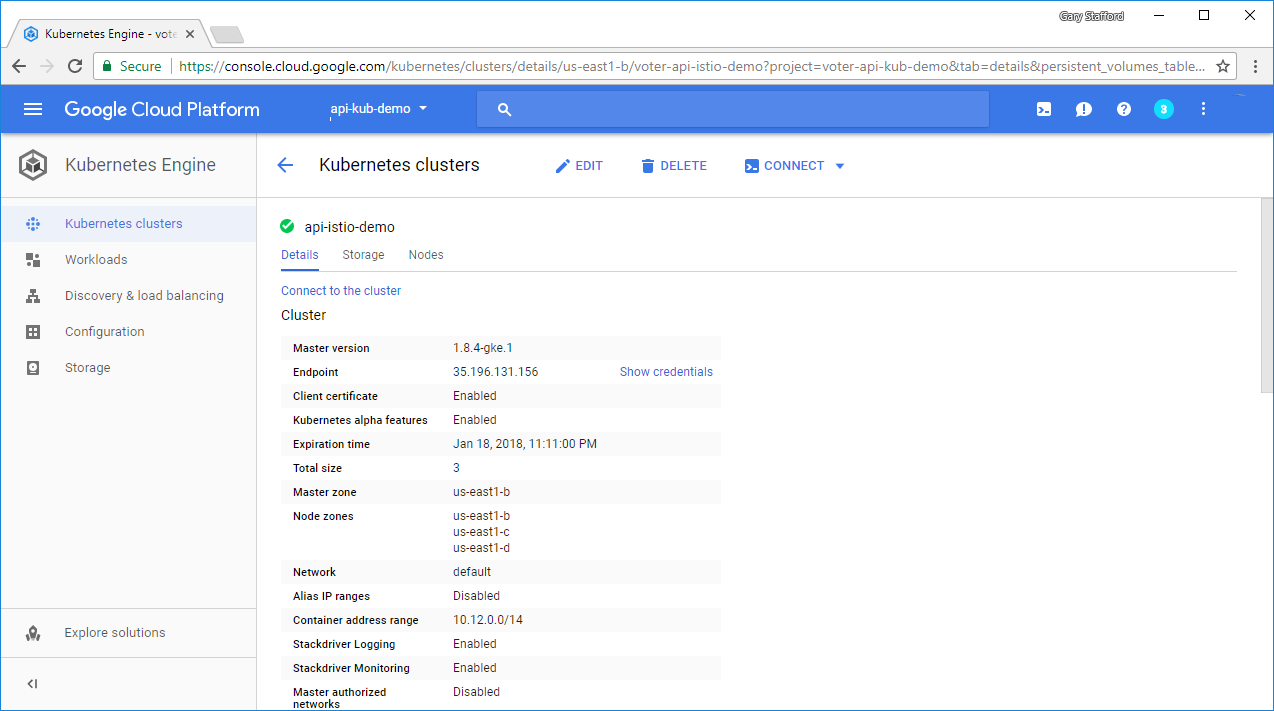
Service-interrupting events can and will happen in your environment. Your network could have an outage, your latest application push might introduce a critical bug, or you might someday have to deal with a natural disaster. When things go wrong, it’s important to have a robust, targeted, and well-tested DR plan for your resources in Google Cloud.
DR Planning Fundamentals
Disaster Recovery (DR) is contained as a subset of business continuity planning. The start of a DR plan can really be simplified by analyzing the business impact of two important metrics:
- Recovery Time Objective (RTO) is the maximum length of time you find acceptable that your application can be offline. Your RTO value is typically defined as part of your service level agreement (SLA).
- Recovery Point Objective (RPO) is the maximum length of time you find acceptable that your application could lose data due to an incident.
In most scenarios, the shorter the RTO and RPO values the more expensive your application will cost to run. Let’s look at a ratio of cost to RTO/RPO
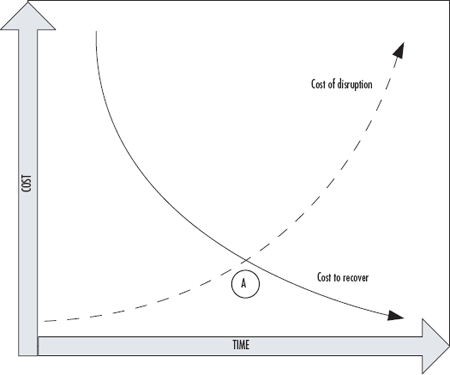
As these smaller RTO and RPO values typically lead to greater complexity, the correlated administrative overhead follows a similar curve. A high-availability application might require you to manage distribution between two physically separated data centers, manage replication, etc.
It’s likely that you are also considering and planning for high availability (HA). HA doesn’t entirely overlap with DR, but it’s important to take HA into account when you’re planning for RTO and RPO values. HA helps to ensure an agreed level of operational performance, usually uptime, for a higher-than-normal period.
Google Cloud in Relation to RTO and RPO
GCP can often reduce the costs associated to RTO and RPO compared to their costs on-premises. \
On-premises DR planning forces you to account for the following requirements
- Capacity: securing enough resources to scale as needed.
- Security: providing physical security to protect assets.
- Network infrastructure: including software components such as firewalls and load balancers.
- Support: making available skilled technicians to perform maintenance and to address issues.
- Bandwidth: planning suitable bandwidth for peak load.
- Facilities: ensuring physical infrastructure, including equipment and power.
Google Cloud, as a highly managed solution, can help you bypass many of these on-premises requirements, removing many of the costs from your cloud DR design.
GCP offers these features that are relevant to DR planning, including:
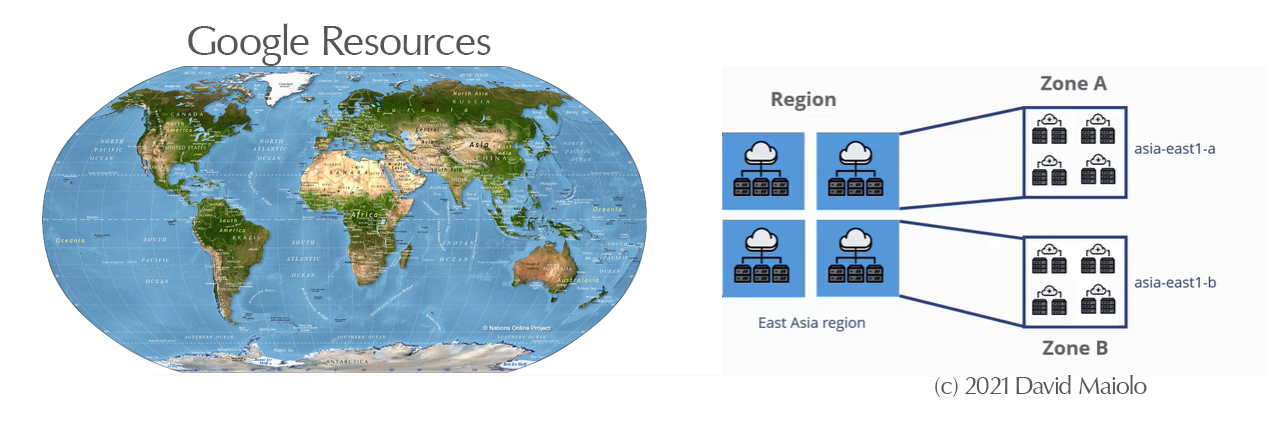
- Global network: Google backbone network uses advanced software-defined networking and edge-caching services
- Redundancy: Multiple points of presence (PoPs) across the globe.
- Scalability: App Engine, Compute Engine autoscalers, and Datastore give you automatic scaling
- Security: The site reliability engineering teams at Google help ensure high availability and prevent abuse of platform resources.
- Compliance: Google undergoes regular independent third-party audits to verify that Google Cloud is in alignment with security, privacy, and compliance regulations and best practices.
The Three Stages of Disaster Recovery Sites
A backup site is a location where you can relocate following a disaster, such as fire, flood, terrorist threat or another disruptive event. This is an integral part of the DR plan and wider business continuity planning of your organization.
- A cold site is an empty operational space with basic facilities like raised floors, air conditioning, power and communication lines etc. Following an incident equipment is brought in and set up to resume operations. It does not include backed up copies of data and information from the original location of the organization, nor does it include hardware already set up.
- A warm site is a compromise between hot and cold. These sites will have hardware and connectivity already established, though on a smaller scale. Warm sites might have backups on hand, but they may not be complete and may be between several days and a week old
- A hot site is a near duplicate of the original site of the organization, with full computer systems as well as complete backups of user data. Real time synchronization between the two sites may be used to completely mirror the data environment of the original site using wide area network links and specialized software.
The terms cold, warm and hot can also be used within DR context to describe patterns that indicate how readily a system can recover when something goes wrong.
Creating Your Disaster Recovery Plan
These are the basic components when creating your DR plan.
- Design to your recovery goals: look at your RTO and RPO values and which DR pattern you can adopt to meet those values. For example, if you have historical non-critical compliance data, you with a large RTO value, a cold DR pattern is likely fine.
- Design for end-to-end recovery: It’s important to make sure your DR plan covers the full recovery process, from backup to restore to cleanup
- Make Disaster Recovery (DR) Tasks Specific: If you need to execute your DR plan, each task should be concrete and unambiguous. For example, “Run the restore script” is too general. In contrast, “Open Bash and run ./restore.sh” is precise and concrete.
Applying Control Measures
Another important component when thinking of DR is how you can potentially precent a disaster before it occurs. For example, add a monitor that sends an alert when a data-destructive flow, such as a deletion pipeline, exhibits unexpected spikes or other unusual activity. This monitor could also terminate the pipeline processes if a certain deletion threshold is reached, preventing a catastrophic situation.
Making Sure Software is Configured for Disaster Recovery
Part of the DR planning is to make sure your software is configured in the event a recovery is needed.
- Verify software can be installed: Make sure that your applications can be installed from source or from a preconfigured image, licensing is available this these apps, and that any Compute Engine resources are available such as pre-allocating VM instances.
- Think of the CD in CI/CD: The Continuous Delivery (CD) component of your CI/CD pipeline is integral to how you deploy applications. As part of your DR plan, consider how this will work in your recovered environment.
Security and Compliance Controls
Often with recovery we are just thinking of how to get our site back online with the least disruption. But don’t forget, security is important. The same controls that you have in your production environment must apply to your recovered environment. Compliance regulations will also apply to your recovered environment.
- Make sure network controls provide the same separation and blocking from as your production environment offered. Think of Shared VPCs and Google Cloud Firewalls.
- Replicate IAM policies to DR environment: IaC methods in Cloud Deployment Manager can help with this.
- After you’ve implemented these security controls in the DR environment. Make sure to test everything.
- Train your users on the DR environment and the steps in the plan.
- Make sure DR meets compliance requirements: only those who need access have access, PII data is redacted and encrypted, etc.
Disaster recovery scenarios for Data
Disaster recovery plans should specify how to avoid losing data during a disaster. The term data here covers two scenarios. Backing up and then recovering database, log data, and other data types fits into one of the following scenarios:
- Data backups: This involves copying od data in discrete amounts from one place to another, such as production site to DR site. Typically, data backups have a small to medium RTO and a small RPO.
- Database backups: These are slightly more complex because they are often centered around a time component. When you think of your database, you might immediately think, from what moment in time is that data? Adopting a high-availability-first approach can help you achieve the smaller RTO and RPO values your DR plan will probably desire.
Let’s look at some different scenarios and how we could achieve a DR plan for these types.
Production Environment is On-Premises
In this scenario, your production environment is on-premises, and your disaster recovery plan involves using Google Cloud as the recovery site.
Data backup and recovery
- Solution 1: Back up to Cloud Storage using a scheduled task
- Create a scheduled task that runs a script or application to transfer the data to Cloud Storage.
- Solution 2: Back up to Cloud Storage using Transfer service for on-premises data
- This service is a scalable, reliable, and managed service that enables you to transfer large amounts of data from your data center to a Cloud Storage bucket.
- Solution 3: Back up to Cloud Storage using a partner gateway solution
- Use a partner gateway between your on-premises storage and Google Cloud to facilitate this transfer of data to Cloud Storage.
Database backup and recovery
- Solution 1: Backup and recovery using a recovery server on Google Cloud
- Backup your database to file backup and transfer to Cloud Storage Bucket. When you need to recover, spin up an instance with database capabilities and restore backup file to instance.
- Solution 2: Replication to a standby server on Google Cloud
- Achieve very small RTO and RPO values by replicating (not just a back up) data and in some cases database state in real time to a hot standby of your database server.
- Configure replication between your on-premises database server and the target database server in Google Cloud
Production Environment is Google Cloud
In this scenario, both your production environment and your disaster recovery environment run on Google Cloud.
Data backup and recovery
A common pattern for data backups is to use a tiered storage pattern. When your production workload is on Google Cloud, the tiered storage system looks like the following diagram. You migrate data to a tier that has lower storage costs, because the requirement to access the backed-up data is less likely.

Database backup and recovery
If you use a self-managed database on Google Cloud such as MySQL, PostgreSQL, or SQL Server as an instance on Computer Engine, you will have similar concerns as with those same databases on-premise. The one bonus here is that you do not need to manage the underlying infrastructure.
A common pattern is to enable recovery of a database server that does not require system state to be synchronized with a hot standby.
If you are using a managed database service in Google Cloud, you can implement appropriate backup and recovery.
- Bigtable provides Bigtable replication. A replicated Bigtable database can provide higher availability than a single cluster, additional read throughput, and higher durability and resilience in the face of zonal or regional failures.
- BigQuery. If you want to archive data, you can take advantage of BigQuery’s long term storage. If a table is not edited for 90 consecutive days, the price of storage for that table automatically drops by 50 percent.
- Firestore. The managed export and import service allows you to import and export Firestore entities using a Cloud Storage bucket
- Spanner. You can use Dataflow templates for making a full export of your database to a set of Avro files in a Cloud Storage bucket
- Cloud Composer. You can use Cloud Composer (a managed version of Apache Airflow) to schedule regular backups of multiple Google Cloud databases.
Disaster recovery scenarios for applications
Let’s frame DR scenarios for applications in terms of DR patterns that indicate how readily the application can recover from a disaster event.
- Batch processing workloads: Tend not to be mission critical, so you typically don’t need to incur the cost of designing a high availability (HA) architecture. Take advantage of cost-effective products such as preemptible VM instances, which is an instance you can create and run at a much lower price than normal instances. (By implementing regular checkpoints as part of the processing task, the processing job can resume from the point of failure when new VMs are launched. This is a warm pattern.
- Ecommerce sites: can have larger RTO values for some components. For example, the actual purchasing pipeline needs to have high availability, but the email process that sends order notifications to customers can tolerate a few hours’ delay. The transactional part of the application needs high uptime with a minimal RTO value. Therefore, you use HA, which maximizes the availability of this part of the application. This approach can be considered a hot pattern.
- Video streaming: In this scenario, an HA architecture is a must-have, and small RTO values are needed. This scenario requires a hot pattern throughout the application architecture to guarantee minimal impact in case of a disaster.

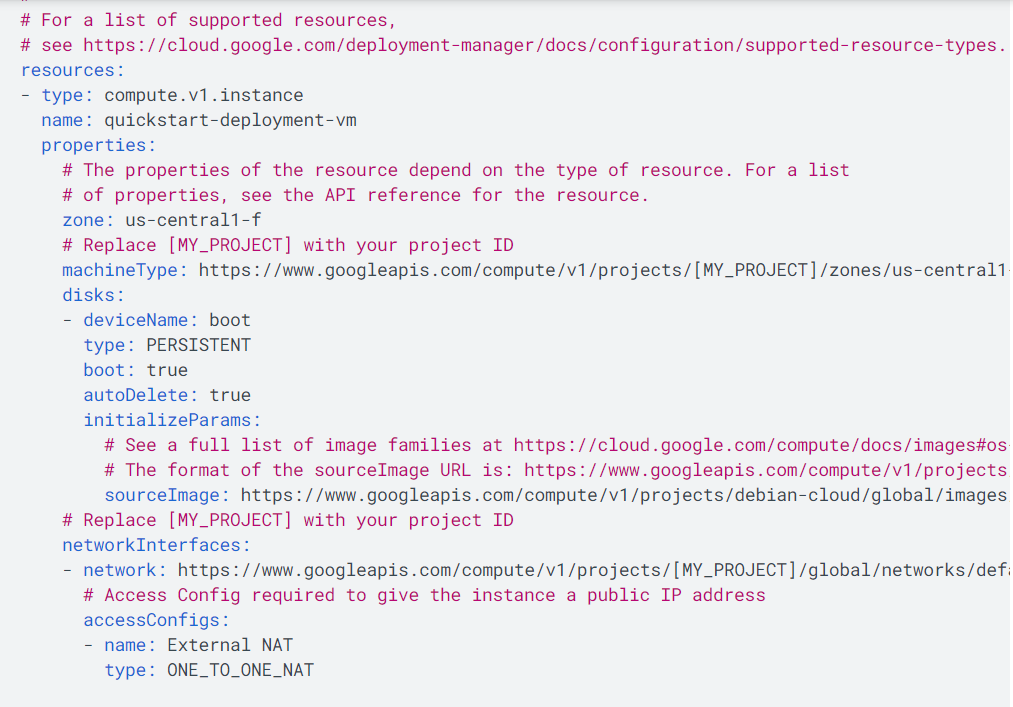 Supported Resource Types and Properties
Supported Resource Types and Properties