The Curious Case of Regular Expressions and Prime Numbers
Prime numbers have fascinated mathematicians for centuries, holding a central place in the foundation of number theory and cryptography. From my background in artificial intelligence and computational systems, I tend to look for practical methods and efficient algorithms to address challenges. However, encountering a seemingly “magical” method to identify prime numbers through purely symbolic means, like regular expressions (or regex), piqued my skeptic yet intrigued mind.
Demystifying the Regex-based Prime Test
The use of regex to determine whether a number is prime may appear esoteric at first. After all, regular expressions are typically used to match strings and patterns in text, not perform arithmetic. The trick lies in how you interpret the input and the clever use of regex syntax and constructs.
This particular prime-checking regex query operates in Python, a language widely used in AI and data science, and involves transforming a number into a specific string form—a tally of ones, for example. Simply put, this process interprets numbers as strings of repeated characters like “1”. It then attempts to break this string down using regular expression patterns to see if it can exactly divide into subgroups, which corresponds to finding whether a number has any divisors other than one and itself. If it does, it is composite; if not, it is prime.
<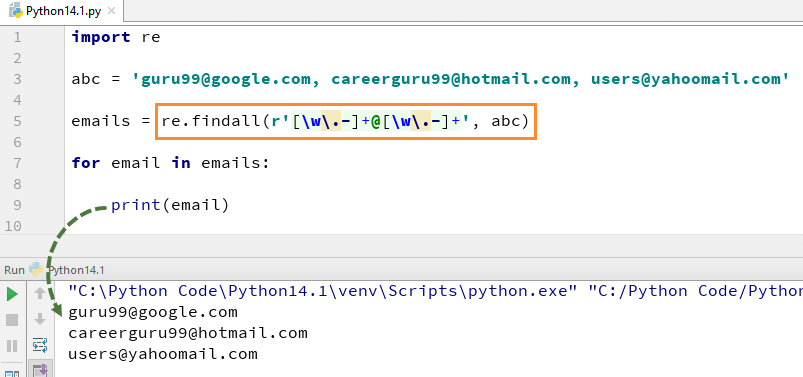 >
>
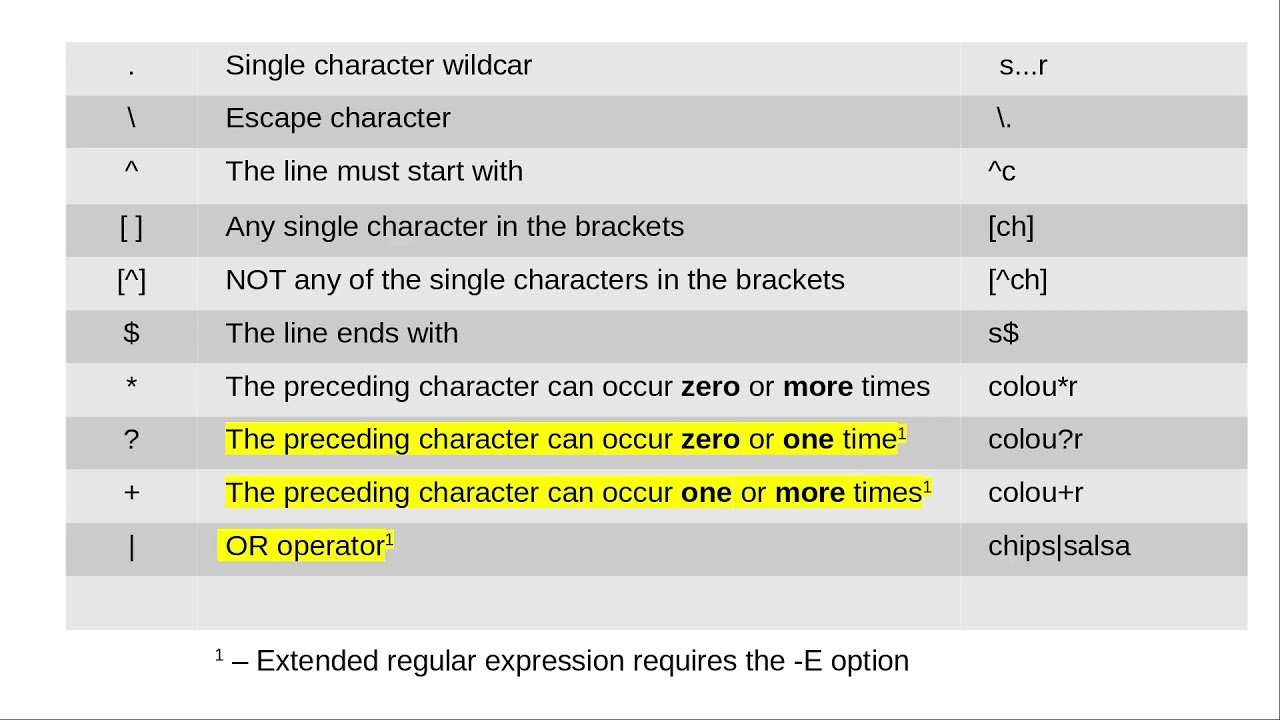
Breaking Down the Regex Symbols
For those unfamiliar with regex syntax, the following can make the prime detection process less “spooky” (though perfect for a Halloween-themed discussion):
- A dot
.represents any character (a wildcard). - A plus
+means “one or more” of the previous element. - The question mark
?makes the matching process “lazy”, stopping at the shortest possible string that matches the regex pattern. - Up arrows
^and dollar signs$indicate the start and end of a string, ensuring the entire sequence is examined. - The forward slash notation
\1calls back to a previous match, allowing the system to reuse prior captured groups—key in testing factors for the number in question.
By leveraging these symbols, regex can efficiently decompose each string of ones (whether it’s “11”, “111”, “1111”, etc.), and check how many ways the string can be evenly rerun back against itself. When no such division exists, the original number is prime.
<
>
A Surprisingly Efficient Algorithm?
One might assume that this method wouldn’t scale well for larger numbers due to the inefficiency of regex at such a task. However, optimizing the string breakdown process—such as using lazy matching—enables this algorithm to avoid some performance hits. It’s an interesting contrast to traditional Sieve of Eratosthenes approaches for prime detection. While regex isn’t typically designed for numerical computation, this clever use shows the linguistic flexibility programming languages like Python offer.
As a former Microsoft Solutions Architect specializing in cloud migration, I’ve often dealt with automation and optimization techniques. Here, Python’s built-in re library handles the brute force nature of regex effectively, which I compare to the optimizations I’ve worked on within AI models for process efficiency and computational scaling.
< >
>
Regular Expressions in the Broader Tech Ecosystem
Aside from mathematical curiosities like prime testing, regex plays an important role in modern computing, especially in information retrieval systems. In previous work on AI search models, for instance, regex patterns are used to streamline database queries or identify information patterns within massive datasets. When scaling or migrating these solutions to the cloud, regex becomes part of the toolkit to ensure data is cleanly parsed, matched, or processed for machine learning models.
< >
>
It All Goes Back to Probability
For readers familiar with my earlier articles on math and probability theory, tying these subjects back to regex patterns might seem unexpected. But probability theory and prime numbers share fundamental connections, especially in cryptography and number theory, where prime distribution characterizes randomness.
While regex might open a symbolic window into prime numbers, it raises a fundamental question: Can symbolic reasoning and pattern-matching methods replace traditional number theory methods in advanced AI or cryptographic functions? The answer, as always, remains nuanced. However, blending computational models like regex with AI frameworks already shows promise in enhancing algorithmic capabilities, such as in machine learning case studies I’ve worked on, where pattern recognition significantly accelerates problem-solving.
Conclusion
Regular expressions may not be the final frontier in prime number research, nor are they likely to replace more optimized algorithmic efficiency tools like the Sieve of Eratosthenes for large-scale computations. But as this clever symbolic solution demonstrates, the lines between symbolic manipulation and numerical computation continue to blur. And in the realm of artificial intelligence, where pattern recognition reigns supreme, methods like regex may prove unexpectedly useful when solving unique computational challenges.
Straddling both the realms of programming and number theory, regex offers us yet another glimpse into the interconnectivity of languages—whether spoken, mathematical, or computational. It’s a great reminder of how diverse techniques can emerge from seemingly unrelated fields, much in the same way as cosmic events can affect technological advances.
Focus Keyphrase: regex prime number detection

 >
> >
> >
> >
> >
> >
> *
* *
*