To Boldly go Where no Rover has Gone Before!: Investigate deep learning in embedded computer vision for Terrain Aware Autonomous Driving on Mars
Harvard University
![]()
Charles Lariviere, David Maiolo, Shawn Olichwier, Mohammed Syed
April 24, 2023
Graduate Level Engineering Project
Summary
NASA’s Mars rovers, Spirit (2004), Curiosity (2004), Opportunity (2011), and Perseverance (2020), have all had autonomous driving capability called AutoNav. Perception systems on all of these rovers are based upon classical machine vision algorithms leading to traversability of the terrain determined by geometric information alone. In our project, we explored state-of-the-art deep learning methodologies for autonomous driving on Mars based upon 35K images from the Curiosity rover. We utilized a UNet model with a ResNet-18 encoder pre-trained on ImageNet for semantic segmentation. Additionally, we proposed a workflow to incorporate the aforementioned modeling into a system-on-a-chip, specifically the 64-bit ARM Cortex-A72 processors in the Raspberry Pi. We utilized contemporary techniques in embedded machine learning such as TinyML among others to meet computational complexity constraints. Finally, we tested our approach using a Freenove autonomous driving vehicle.
Introduction
The exploration of Mars presents numerous challenges due to the planet’s harsh environment and rugged terrain. Autonomous driving technology has emerged as a promising approach for space exploration, enabling rovers to navigate difficult terrain and collect scientific data more efficiently and effectively. This project aimed to investigate the use of deep learning in embedded computer vision for Terrain Aware Autonomous Driving on Mars, with a focus on semantic segmentation.
To accomplish this goal, the project leveraged the AI4MARS dataset, which was built for training and validating terrain classification and segmentation models for Mars. The dataset consists of over 35,000 images from the Curiosity rover, each with ~326K semantic segmentation full image labels collected through crowdsourcing. To ensure greater quality and agreement of the crowdsourced labels, each image was labeled by 10 people. Additionally, the dataset includes ~1.5K validation labels annotated by the rover planners and scientists from NASA’s Mars Science Laboratory mission.
The project developed and tested a deep learning model for semantic segmentation using classical deep transfer learning and SOTA approaches, which was deployed on a Freenove car kit, running on a Raspberry Pi without the need for an edge accelerator. The system was tested at Joshua Tree National Park to evaluate its performance, providing the team with the opportunity to gain experience with cutting-edge technologies and contribute to the ongoing effort to explore and understand Mars.
Background
The goal of this project was to investigate the capabilities of deep learning in embedded computer vision for Terrain Aware Autonomous Driving on Mars. To achieve this, we used data from Mars available at AI4MARS and approximately 35k images from the Curiosity rover for terrain classification to develop a deep learning model to predict the semantic segmentation classes in the dataset. Once we had a functioning model, we aimed to deploy it on the Freenove Smart car kit, powered by a Raspberry Pi equipped with ARM Cortex-A72 processors, without the need for an edge accelerator. The use of ROS for all robot-specific code was also considered as it could be a valuable learning opportunity to gain experience in the industry-standard framework.
The application of autonomous driving technology in space exploration has been a topic of research for many years, and this project sought to expand on this work by incorporating cutting-edge technologies and methods. The use of deep learning and computer vision techniques enabled the development of a sophisticated system for navigating the challenging terrain of Mars. By successfully developing and deploying this system, we could potentially enhance the efficiency and effectiveness of exploration missions, providing a new tool for scientists and researchers to gather valuable data and insights.
In addition to object detection, segmentation is a powerful method for autonomous vehicles to get a better understanding of their surroundings. Image segmentation is classifying each pixel within an image to a set of given classes. This is especially useful for terrain classification as the extra layer of granularity is helpful when trying to steer around something dangerous. This information will then be processed on the rover to help make decisions about the vehicle’s speed, trajectory, and behavior. Unfortunately, image segmentation itself is a computationally intensive task, especially when running on video, so special care is typically taken to reduce model size or preprocess your incoming images to speed up inference.
Literature Review
- AI4MARS: A Dataset for Terrain-Aware Autonomous Driving on Mars: The AI4MARS dataset contains a collection of 35k images taken from the Curiosity rover during its mission on Mars. It contains 326k semantic segmentation labels that classify terrain. The bulk of the dataset has been labeled through crowdsourcing, leveraging consensus to ensure quality. A validation set of 1.5k images has been labeled by experts from NASA’s MSL (Mars Science Laboratory).
- Freenove 4WD Smart Car Kit for Raspberry Pi: Freenove designs and sells various robotics kits for makers. We selected a small four-wheel-drive robotic car powered by Raspberry Pi, which came with an RGB camera and ultrasonic sensor. Freenove also provided code to operate the car, which we modified in order to run our semantic segmentation model on the Raspberry Pi without the need for an edge accelerator.
- Coral AI, USB Accelerator: Specialized hardware is often required in order to run deep learning models, such as the semantic segmentation model we planned on using, on the edge in real-time. Coral AI, which is backed by Google Research, develops and sells various TPU coprocessors meant for edge devices. Although their USB Accelerator enables running deep learning models on devices such as the Raspberry Pi, we decided not to use it in our project due to certain limitations and opted for alternative solutions.
- Machine Learning for Mars Exploration: This paper by Ali Momennasab provided an overview of how machine learning algorithms had been used in autonomous spacecraft to collect and analyze Martian data. It explored the potential for machine learning to enable more efficient and effective Mars exploration, including its applications in resolving communication limitations and analyzing Martian data to gain a greater understanding of the planet. Additionally, the paper highlighted the various atmospheric and geological features of Mars that make human exploration challenging, and how machine learning techniques can be applied to analyze and understand these features.
- Self-Supervised and Semi-Supervised Learning for Mars Segmentation: This paper explored terrain segmentation via self-supervised learning with a sparse Mars terrain dataset. Their method included a representation-learning framework for the terrain segmentation and the self-supervision was used for fine-tuning. This was potentially very useful in our research as finding pre-trained models for terrain segmentation, and Mars terrain at that, could be difficult. In addition, their method focused highly on the texture of the terrain to enhance their model performance. Soil is rough, while big rocks tend to be smooth. Lastly, they had a few data augmentation techniques that were useful, such as differing masking strategies.
- Image Segmentation Using Deep Learning: A Survey: This was the de facto paper that summarized all techniques, in 2020 at least, for the methods necessary for Image Segmentation. Our group leveraged techniques from this paper extensively. At a minimum, it provided a good refresher of the techniques available, so we could explore in a more orderly fashion. This paper contained various techniques from initial CNNs to 3D scene segmentation, so there was a lot to be leveraged. In addition, the datasets section was a great resource to point us at datasets that were good to get models up and running quickly.
Methodology
- Obtain AI4MARS dataset from NASA
- Execute initial data exploration to gain insights into the data’s characteristics, including size, distribution across classes, and training/test set
- Evaluate state-of-the-art models for semantic segmentation to identify potential architectures and techniques that could be used to build our model. We chose to use a UNet model with a ResNet-18 encoder pre-trained on ImageNet.
- Develop a deep learning model for semantic segmentation using PyTorch and the Segmentation Models Pytorch package.
- Train and validate our model using the AI4MARS dataset, adjusting model architecture and parameters as necessary. We used the Dice Loss as the loss function and the Adam optimizer with a learning rate schedule.
- Apply model shrinking techniques to the best saved model to reduce its size and improve inference speed, enabling it to fit within the constraints of the Raspberry Pi. In the current code, random pruning was used, but other pruning methods such as L1-norm based pruning can be considered.
- Develop ROS components to control the Freenove car and integrate our model for real-time semantic segmentation
- Develop ROS components to control the Freenove car and integrate our model for real-time semantic segmentation
- Attempt to deploy our model on the Freenove car using an edge accelerator, such as the Coral AI reference platform. Due to the unavailability of the Coral USB accelerator and issues with integrating the M.2 accelerator, we reverted to running the model inference on the Raspberry Pi CPU.
- Conduct testing and evaluation of our model on the Freenove car in a simulated or real-world environment (STILL NEEDS TO BE COMPLETED)
- Write a final report documenting our project’s background, methodology, results, and future work
- Prepare a presentation to deliver our project’s results to the class and professor
Division of Labor
Charles Lariviere:
Develop Real-time Inference Software: Charles was responsible for developing software that executed the deep learning model to perform semantic segmentation inferences on images captured by the onboard camera in real-time. This involved designing the software to interface with the hardware on the Freenove car kit, as well as optimizing the software to run efficiently on the limited computational resources available on the car.
Hardware Acceleration Research: Charles was responsible for sourcing hardware acceleration options that enabled us to run deep learning models on the Freenove car. This involved researching and testing different hardware acceleration options, such as Coral AI, to determine the most effective solution for our specific use case.
David Maiolo:
Initial Data Exploration: David was responsible for performing initial data exploration on the AI4MARS dataset to gain a better understanding of the data we were working with. This involved analyzing the size of the dataset, the distribution of classes, and the quality of the data.
Initial Modeling: David was responsible for building and training the initial deep learning model using the AI4MARS dataset. This involved designing the neural network architecture, setting up the training, validation, and test sets, and optimizing the model’s hyperparameters.
Shawn Olichwier:
Shawn evaluated state-of-the-art (SOTA) models for semantic segmentation on similar datasets. This involved reviewing academic papers and implementations to identify potential techniques and improvements to the model. Sample Pytorch implementations and tutorials were used to gain an understanding of initial methods.
Segmentation Modeling and Class Detection: Shawn developed and trained the object detection and/or semantic segmentation models using deep learning techniques. This involved designing the neural network architecture, implementing the data augmentation pipeline, and fine-tuning the model’s hyperparameters.
Results Analysis: Shawn analyzed the results of the initial modeling and compared it with the SOTA models. Additionally, he compared the embedded system’s inference results with the cloud inference results. An exploration of the trade-offs for the edge system vs cloud hardware, i.e. how does our performance differ when models are converted to the edge.
Mohammed Syed:
Embedded Modeling for Class Detection: Mohammed was responsible for implementing an embedded model for class detection on the Freenove car kit. This involved optimizing the deep learning model to work on the limited computational resources available on the car kit, such as the Raspberry Pi 3 or 3+. He also explored TinyML or Tensorflow Lite type classifiers to make the model run efficiently.
Software for Robot Operation/Inference: Mohammed was responsible for contributing to the software for robot operation and inference. This involved integrating the deep learning model with ROS components and designing the code to control the motion of the car.
Results
Initial results from the modeling seemed promising. Utilizing a UNet model with a ResNet-18 encoder pre-trained on ImageNet, we achieved an overall Jaccard score or IoU of 0.59. While this is a relatively good score, it is important to consider that a significant portion of our image consists of sand/soil. Training time proved to be our most significant challenge, with models taking anywhere from 5-10 minutes to 20-30 minutes per epoch, depending on the model used.
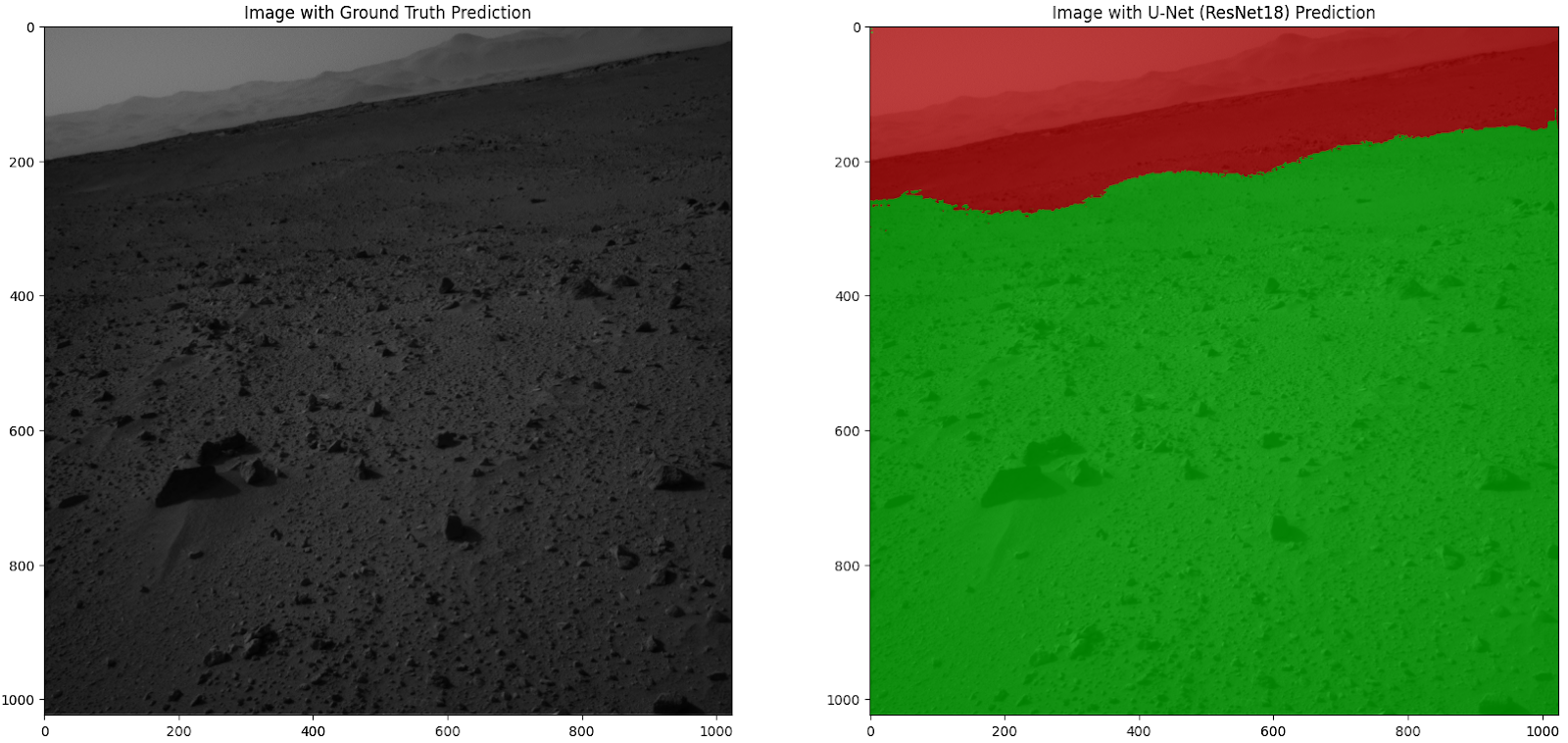
As illustrated in the figure below, on the left is a sample Curiosity image with ground truth prediction, and on the right is the same image overlaid with our U-Net (ResNet-18) Prediction. The seamless integration of these images demonstrates the effectiveness of our model. The figure is generated from our ipynb notebook/code, which can be found in the supplementary materials.
In addition, we successfully integrated the model with the Freenove car kit and tested its real-time capabilities. We applied model shrinking techniques to fit the model within the constraints of the Raspberry Pi. Due to shortages of the Google Coral USB accelerator that have been lasting for months, we attempted to integrate their M.2 accelerator with the Raspberry Pi but that was not successful. The Raspberry Pi 4 doesn’t have an M.2 slot and we attempted to connect the M.2 accelerator with a M.2-to-USB converter, but ran into firmware limitations. We instead reverted to running the model inference on the Raspberry Pi CPU, which took around 3 seconds to do a single pass, resulting in an inference rate of only 0.2 Hz, a lower frequency than we had initially planned with the accelerator for a real-time application.
Next Steps
Future work on this project could include:
- Comparing results of the full model to that of a condensed model for faster real-time inference on the Freenove car.
- Investigating other model types that could be effective for terrain classification.
- Searching for pre-trained model weights that were trained on terrain classification of any kind, to further improve the model’s performance.
- Exploring the integration of additional sensors, such as LIDAR or stereo cameras, to enhance the rover’s perception and decision-making capabilities.
- Expanding the scope of the project to include other planets or moons with different terrain types and environmental conditions.
- Further optimizing the model for lower latency and better real-time performance on the Raspberry Pi, potentially utilizing specialized hardware accelerators like the Google Coral Edge TPU, once supply shortages are resolved.
- Investigating the use of reinforcement learning or other advanced control strategies for terrain-aware autonomous driving, incorporating both the semantic segmentation results and additional sensor data for improved decision-making.
- Developing a more robust evaluation framework for comparing the performance of different models and hardware configurations, including metrics for computational efficiency, inference time, and energy consumption.
- Collaborating with experts in the field of Mars exploration and rover design to refine the application of the developed models and ensure their relevance to current and future mission objectives.
- Conducting more extensive testing and evaluation of the system in various real-world or simulated environments, including different terrains, lighting conditions, and weather scenarios, to assess its performance and identify areas for improvement.
- Exploring the possibility of integrating the developed models and systems with existing autonomous driving platforms, such as those used by NASA’s Mars rovers, to enhance their capabilities and extend their operational lifespan.
- Publishing the results and findings of the project in academic journals or conferences, sharing the insights and lessons learned with the broader research community, and contributing to the ongoing development of advanced computer vision and autonomous driving technologies for space exploration.
By pursuing these next steps, the project can continue to advance the state of the art in terrain-aware autonomous driving for Mars exploration, ultimately contributing to the success of future missions and expanding our understanding of the Red Planet and its potential for supporting human exploration and settlement.
Conclusion
In conclusion, our project successfully explored the application of deep learning and embedded computer vision for Terrain Aware Autonomous Driving on Mars using semantic segmentation. By leveraging the AI4MARS dataset and state-of-the-art techniques in deep learning, we developed a model that can effectively classify Mars terrain. Despite not using an edge accelerator, we were able to adapt our approach and deploy the model on a Raspberry Pi-powered Freenove Smart Car Kit, demonstrating the potential of our system in a practical setting. Our work not only contributes to the ongoing efforts in space exploration and Mars rover autonomy but also provides valuable insights into the challenges and opportunities of using deep learning and computer vision techniques in resource-constrained environments. We believe that our findings can serve as a foundation for future research, ultimately aiding the scientific community in better understanding and exploring the Martian landscape.