Dimensionality Reduction: The Key to Advancing Large Language Models

The Essential Role of Dimensionality Reduction in Advancing Large Language Models
In the ever-evolving field of machine learning (ML), one topic that stands at the forefront of innovation and efficiency is dimensionality reduction. Its impact is most keenly observed in the development and optimization of large language models (LLMs). LLMs, as a subset of artificial intelligence (AI), have undergone transformative growth, predominantly fueled by advancements in neural networks and reinforcement learning. The journey towards understanding and implementing LLMs requires a deep dive into the intricacies of dimensionality reduction and its crucial role in shaping the future of AI.
Understanding Dimensionality Reduction
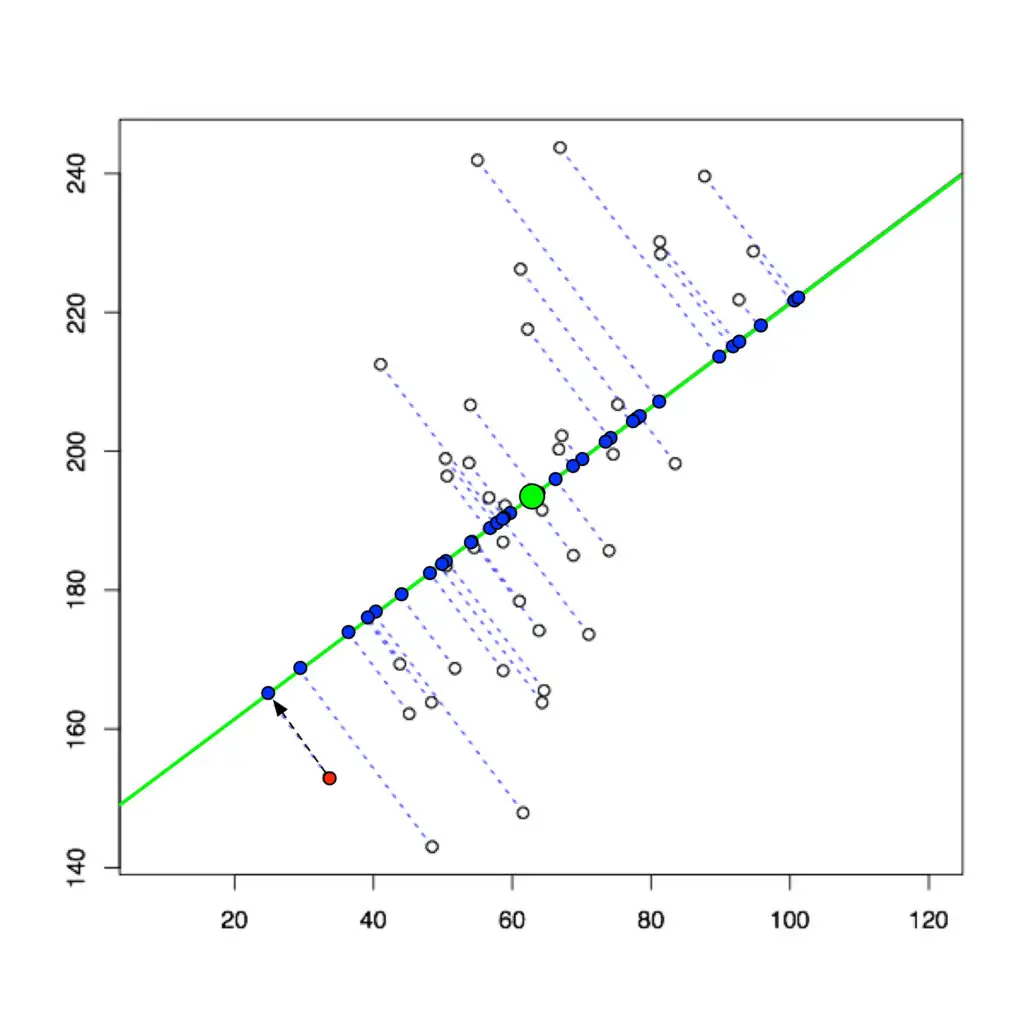
Dimensionality reduction is the process of reducing the number of random variables under consideration, by obtaining a set of principal variables. In the context of LLMs, it helps in simplifying models without significantly sacrificing the quality of outcomes. This process not only enhances model efficiency but also alleviates the ‘curse of dimensionality’—a phenomenon where the feature space becomes so large that model training becomes infeasibly time-consuming and resource-intensive.
For a technology consultant and AI specialist, like myself, the application of dimensionality reduction techniques is an integral part of designing and deploying effective machine learning models. Although my background in AI, cloud solutions, and legacy infrastructure shapes my perspective, the universal principles of dimensionality reduction stand solid across varied domains of machine learning.
Methods of Dimensionality Reduction
The two primary methods of dimensionality reduction are:
- Feature Selection: Identifying and using a subset of the original features in the dataset.
- Feature Extraction: Creating new features from the original set by combining or transforming them.
Techniques like Principal Component Analysis (PCA), t-Distributed Stochastic Neighbor Embedding (t-SNE), and Linear Discriminant Analysis (LDA) are frequently employed to achieve dimensionality reduction.
Impact on Large Language Models
Dimensionality reduction directly influences the performance and applicability of LLMs. By distilling vast datasets into more manageable, meaningful representations, models can accelerate training processes, enhance interpretability, and reduce overfitting. This streamlined dataset enables LLMs to better generalize from training data to novel inputs, a fundamental aspect of achieving conversational AI and natural language understanding at scale.
Consider the practical implementation of an LLM for a chatbot. By applying dimensionality reduction techniques, the chatbot can rapidly process user inputs, understand context, and generate relevant, accurate responses. This boosts the chatbot’s efficiency and relevance in real-world applications, from customer service interactions to personalized virtual assistants.
< >
>
Challenges and Solutions
Despite the advantages, dimensionality reduction is not without its challenges. Loss of information is a significant concern, as reducing features may eliminate nuances and subtleties in the data. Moreover, selecting the right technique and parameters requires expertise and experimentation to balance complexity with performance.
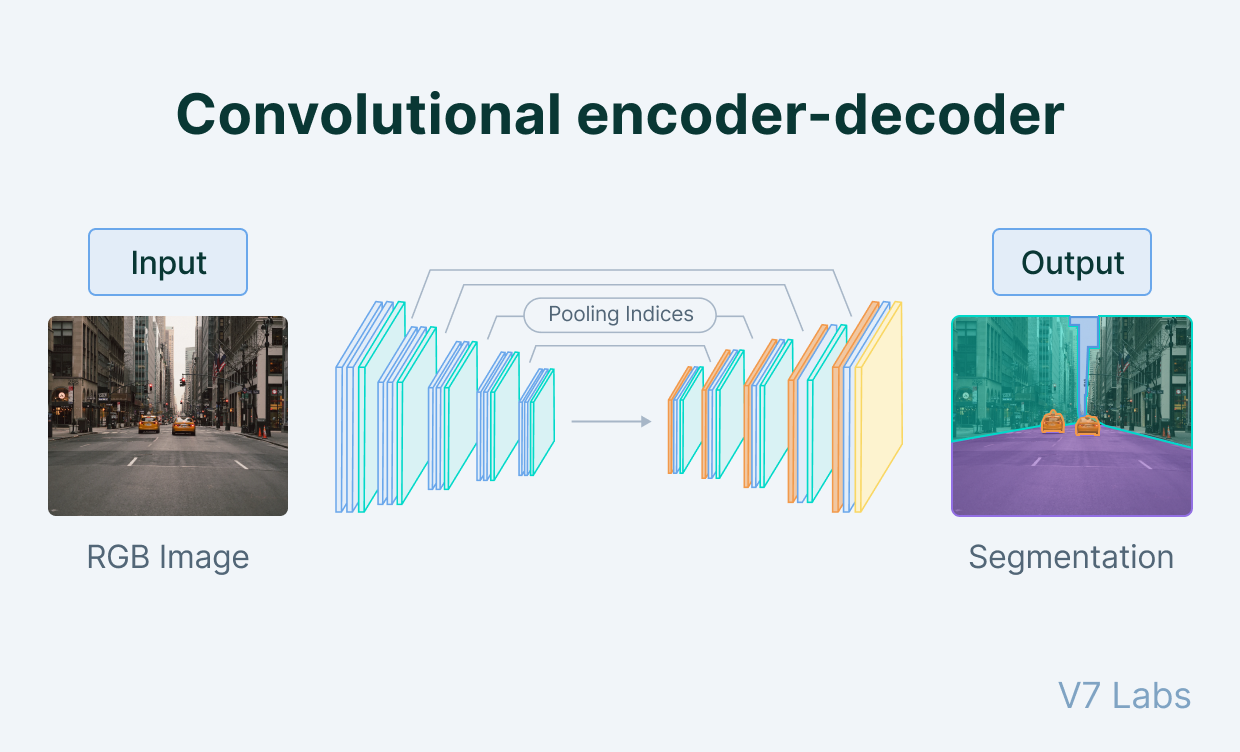
To mitigate these challenges, machine learning engineers and data scientists employ a combination of methods and rigorously validate model outcomes. Innovative techniques such as Autoencoders in deep learning have shown promise in preserving essential information while reducing dimensionality.
< >
>
Looking Ahead
As AI continues its march forward, the relevance of dimensionality reduction in developing sophisticated LLMs will only grow. The ongoing research and development in this area are poised to unveil more efficient algorithms and techniques. This evolution will undoubtedly contribute to the creation of AI systems that are not only more capable but also more accessible to a broader range of applications.
In previous discussions on machine learning, such as the exploration of neural networks and the significance of reinforcement learning in AI, the importance of optimizing the underlying data representations was a recurring theme. Dimensionality reduction stands as a testament to the foundational role that data processing and management play in the advancement of machine learning and AI at large.
Conclusion
The journey of LLMs from theoretical constructs to practical, influential technologies is heavily paved with the principles and practices of dimensionality reduction. As we explore the depths of artificial intelligence, understanding and mastering these techniques becomes indispensable for anyone involved in the field. By critically evaluating and applying dimensionality reduction, we can continue to push the boundaries of what’s possible with large language models and further the evolution of AI.
< >
>
Focus Keyphrase: Dimensionality Reduction in Large Language Models








Thanks everyone for reading! I’m thrilled to share insights on how dimensionality reduction is reshaping the development of large language models. This topic fascinates me because it stands at the intersection of efficiency and innovation in AI. I hope this piece demystifies some of the complexity around LLMs and sparks further discussion in our community about the future of artificial intelligence.
Interesting read, David. While I share enthusiasm for the progression of AI, my skepticism concerns the trade-off between model simplicity and the richness of outputs. Dimensionality reduction indeed accelerates training and presumably application, yet do we risk oversimplifying human language nuances? It’s a delicate balance, one that should be tread with both optimism and caution. As a network engineer, I appreciate the technological strides, but I advocate for a balanced appreciation of what complexity brings to AI, especially in language models.