Exploring Reinforcement Learning and Large Language Models: A Deep Dive

Advancing the Frontier: Deep Dives into Reinforcement Learning and Large Language Models
In recent discussions, we’ve uncovered the intricacies and broad applications of machine learning, with a specific focus on the burgeoning field of reinforcement learning (RL) and its synergy with large language models (LLMs). Today, I aim to delve even deeper into these topics, exploring the cutting-edge developments and the potential they hold for transforming our approach to complex challenges in AI.
Reinforcement Learning: A Closer Look
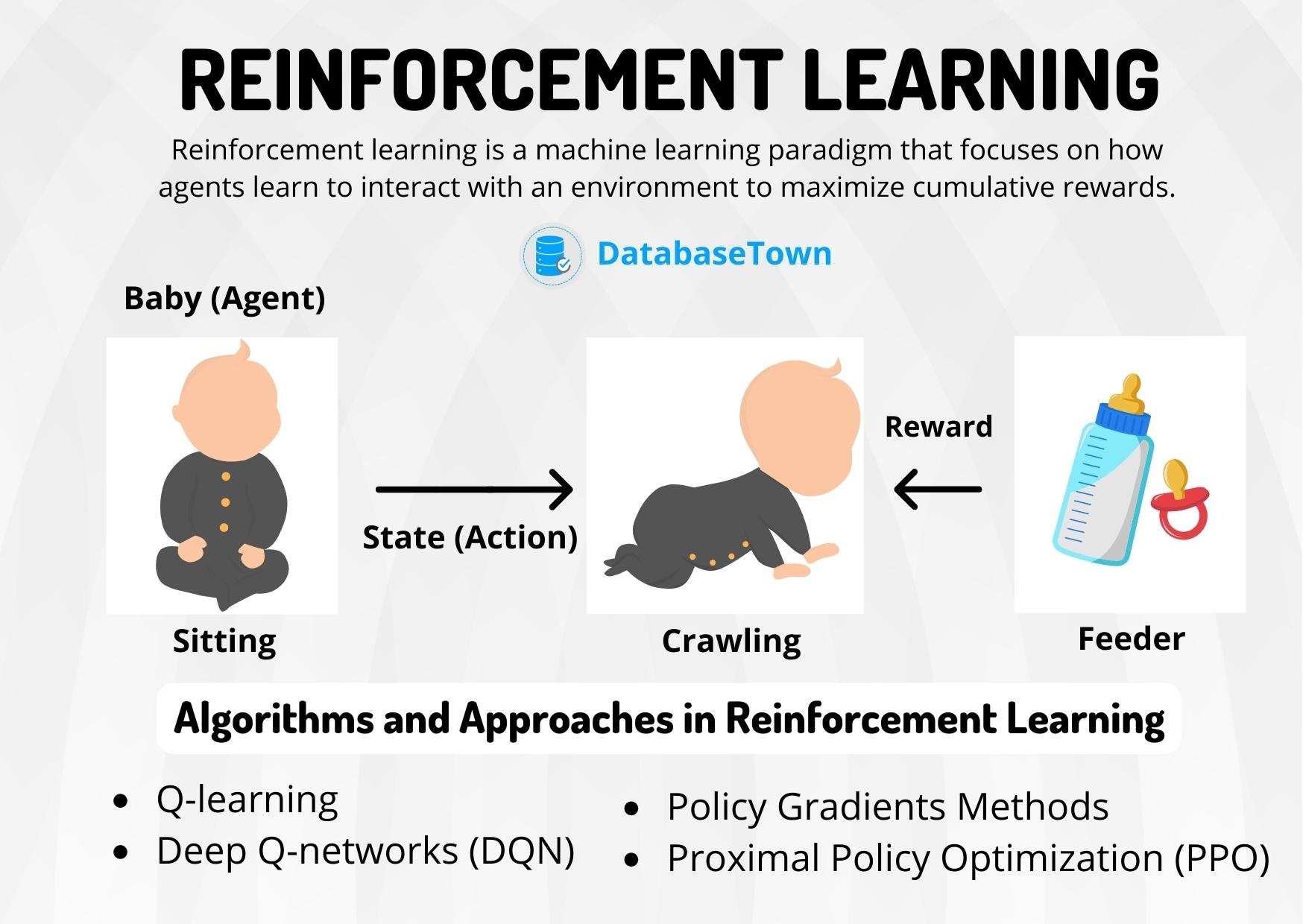
Reinforcement learning, a paradigm of machine learning, operates on the principle of action-reward feedback loops to train models or agents. These agents learn to make decisions by receiving rewards or penalties for their actions, emulating a learning process akin to that which humans and animals experience.
< >
>
Core Components of RL
- Agent: The learner or decision-maker.
- Environment: The situation the agent is interacting with.
- Reward Signal: Critically defines the goal in an RL problem, guiding the agent by indicating the efficacy of an action.
- Policy: Defines the agent’s method of behaving at a given time.
- Value Function: Predicts the long-term rewards of actions, aiding in the distinction between short-term and long-term benefits.
Interplay Between RL and Large Language Models
The integration of reinforcement learning with large language models holds remarkable potential for AI. LLMs, which have revolutionized fields like natural language processing and generation, can benefit greatly from the adaptive and outcome-oriented nature of RL. By applying RL tactics, LLMs can enhance their prediction accuracy, generating more contextually relevant and coherent outputs.
RL’s Role in Fine-tuning LLMs
One notable application of reinforcement learning in the context of LLMs is in the realm of fine-tuning. By utilizing human feedback in an RL framework, developers can steer LLMs towards producing outputs that align more closely with human values and expectations. This process not only refines the model’s performance but also imbues it with a level of ethical consideration, a critical aspect as we navigate the complexities of AI’s impact on society.
Breaking New Ground with RL and LLMs
As we push the boundaries of what’s possible with reinforcement learning and large language models, there are several emerging areas of interest that promise to redefine our interaction with technology:
- Personalized Learning Environments: RL can tailor educational software to adapt in real-time to a student’s learning style, potentially revolutionizing educational technology.
- Advanced Natural Language Interaction: By fine-tuning LLMs with RL, we can create more intuitive and responsive conversational agents, enhancing human-computer interaction.
- Autonomous Systems: Reinforcement learning paves the way for more sophisticated autonomous vehicles and robots, capable of navigating complex environments with minimal human oversight.
< >
>
Challenges and Considerations
Despite the substantial progress, there are hurdles and ethical considerations that must be addressed. Ensuring the transparency and fairness of models trained via reinforcement learning is paramount. Moreover, the computational resources required for training sophisticated LLMs with RL necessitate advancements in energy-efficient computing technologies.
Conclusion
The confluence of reinforcement learning and large language models represents a thrilling frontier in artificial intelligence research and application. As we explore these territories, grounded in rigorous science and a deep understanding of both the potential and the pitfalls, we edge closer to realizing AI systems that can learn, adapt, and interact in fundamentally human-like ways.
< >
>
Continuing the exploration of machine learning’s potential, particularly through the lens of reinforcement learning and large language models, promises to unlock new realms of possibility, driving innovation across countless domains.








Leave a Reply
Want to join the discussion?Feel free to contribute!